chatGPT的诞生宣告了通向强人工智能的道路上出现了曙光,Chat-GPT的成功也激发了更多的研究机构和企业的研发斗志和热情,纷纷投入到大模型研发热潮之中,形成“百模竞发”的局面,促进了大模型的研发和优化升级,形成“百家争鸣、百花齐放”的发展态势。
随着深度学习技术的迅速发展,基于大模型的人工智能系统在自然语言处理领域已经取得了显著的进展,展现出强大的语言理解和生成能力,使其在各行各业具有广阔的应用前景。面向生物医学领域,大语言模型有助于提升医生与患者之间的沟通,提供有用的医学信息,并在辅助诊疗、生物医学知识发现、个性化医疗方案等方面具有巨大潜力。然而,在人工智能社区中,已有的开源生物医学大模型相对较少,且大多主要专注于单语(中文或英语)的医疗问答对话任务。
近日,计算机学院信息检索研究室(DUTIR)罗凌、杨志豪、王健、林鸿飞老师及其团队在生物医学大模型领域的研究取得进展,研发了中英双语生物医学大模型——太一(Taiyi),旨在探索大模型在生物医学领域中双语自然语言处理多任务的能力。团队开源了中英双语数据集整理信息、“太一”大模型权重、模型推理使用脚本,并搭建了Demo开放测试,具体信息见项目地址:https://github.com/DUTIR-BioNLP/Taiyi-LLM。
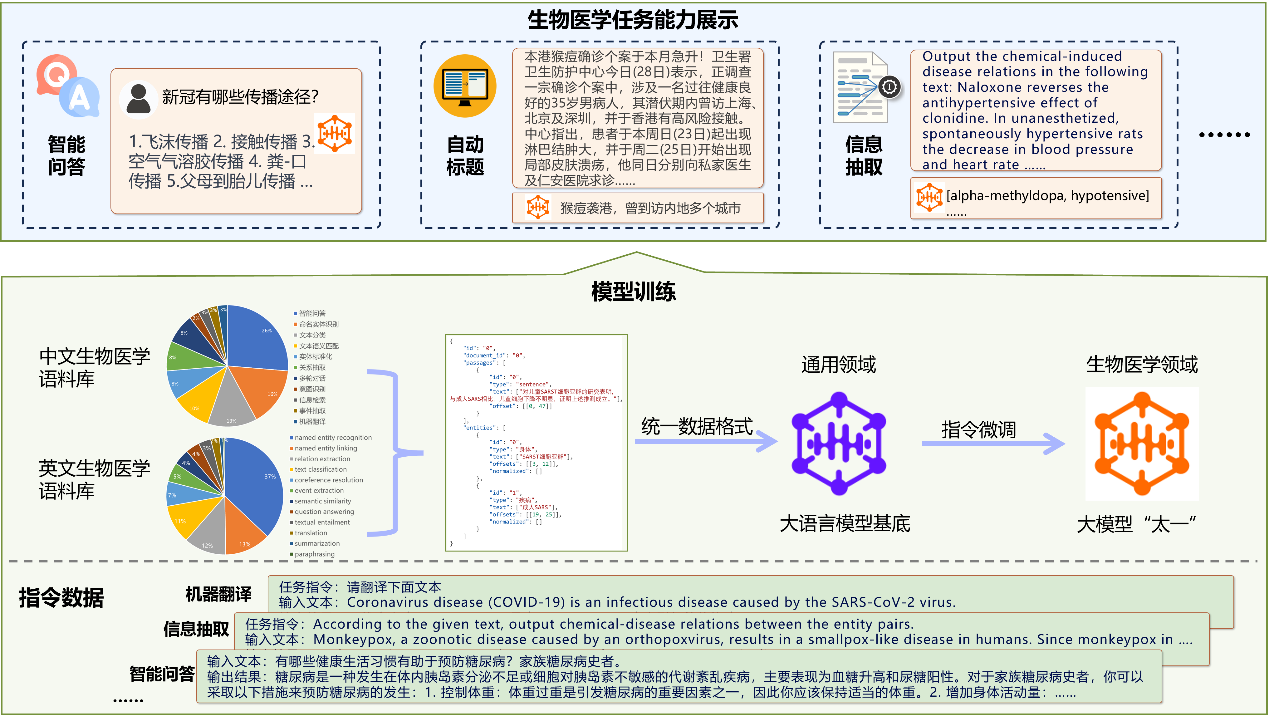
“太一”大模型整体框架图
“太一”大模型通过问答对话形式与用户进行交互,可进行病情咨询、疾病预防、药物咨询、信息抽取等多种丰富生物医学主题相关任务,有助于更有效地管理生物医学信息,提高医疗决策的质量,提升生物医学教育的效果等,为智慧医疗领域带来了很多的可能性。“太一”大模型具有以下三大特点:
丰富的生物医学训练资源:团队收集整理了丰富的中英双语生物医学自然语言处理(BioNLP)训练语料,其中包含38个中文数据集,102个英文数据集,覆盖十余种生物医学任务。
出色的中英双语多任务能力:通过丰富的中英双语任务指令数据(超过100W条样本)进行微调,使模型具备较出色的双语生物医学智能问答、医学对话、报告生成、信息抽取、机器翻译、标题生成、文本分类等多种BioNLP能力。
优秀的泛化能力:除生物医学领域,模型仍具备通用领域对话能力,并通过设计指令模板多样性,使模型具备了较优秀的指令理解能力,在同类任务的不同场景下具有较好的泛化能力,并激发了模型一定的零样本学习能力。
部分样例展示:
智能问答和对话能力

信息抽取能力

机器翻译能力

与现存的生物医学领域大模型侧重于单语医疗问答对话任务不同,“太一”不仅在双语对话问答方面表现出色,还利用丰富的高质量人工标注生物医学数据集进行指令微调,挖掘了大模型在生物医学领域的多任务潜力。这使得“太一”在处理现实生物医学复杂场景任务时更有通用性,并为智慧医疗领域的发展带来了更多可能性。
尽管“太一”在多项BioNLP任务上展示了优良的性能,但一些复杂任务(如医疗报告生成、事件抽取等)效果还有很大提升空间。此外,目前“太一”大模型仍存在大模型的一些常见缺点,例如误解、幻觉、信息有限性、偏见、多轮长对话能力较不稳定、话题转换能力弱等。在未来的工作中,团队也将在增量预训练、强化学习性能增强、可解释性、安全性等方面进一步深入研究,以提升“太一”的能力。
